FOSDEM 2026. A weekend of tech talks and beer
I am back at FOSDEM, in Brussels. Unlike last year, I flew in for the weekend. The bus was terribly late. And here’s the first situation I found myself in:

Having confirmed with one of the volunteers that the queue situation was a real thing indeed, I hurried back to the end of the line. What if I don’t get in? Ten to twenty minutes later, a flock of people got out of the stadium-like auditorium, and every one of us found ourselves a seat inside. Patience pays off!
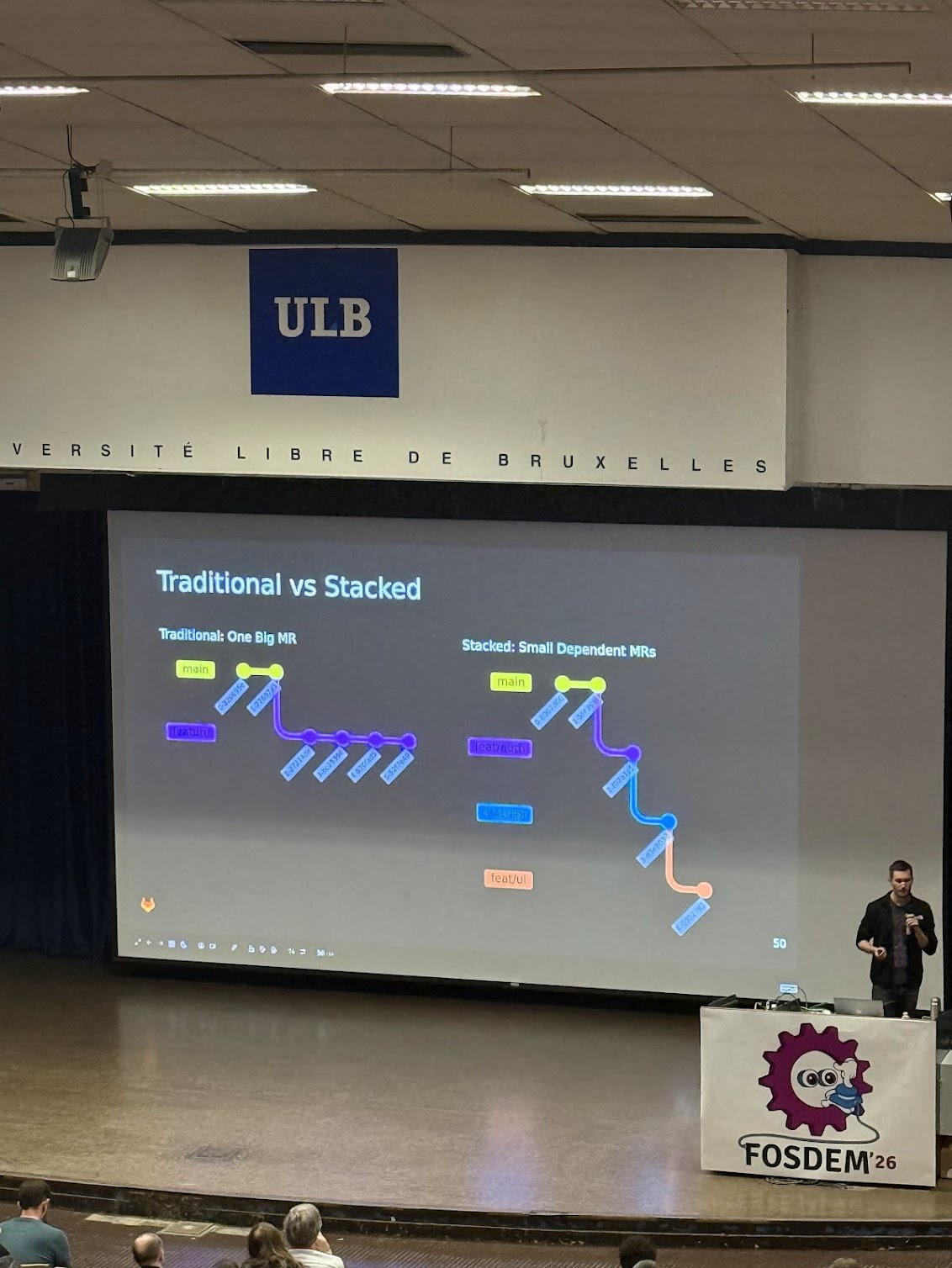
The Future of Git: What’s Next?

Now we are back! A Git maintainer / GitLab staff engineer revealed that developer experience is their key priority. Sourcing inspiration from Jujutsu — a Git-compatible frontend.
Some features to watch for: we’ll be able to switch branches without stashing (essentially auto-commit). We’ll be able to edit commits. Child branches will automatically rebase on parent updates.
Maintainers will on enabling stronger SHA-256 (instead of SHA-1) hash functions for file checksums, reducing the chance of someone sneaking in malicious code with the same hash but different contents.
Overall, an okay keynote, though it spent too much time on the details.
Lightning talks - love the format!
Afterwards, I rushed to the databases hall, where the lightning talks had already started. Now, this was the FOSDEM I remembered — punchy five-minute talks, perfect for our TikTok fried brains.
RonDB: Unified ML Feature Stores

The first talk on the line was the RonDB session. RonDB promises to unify both offline and online stores (think classical BigQuery / ClickHouse + Redis) into a single database for ML feature building and serving. That’s a nice operational benefit. In my current place, though, we already benefit a lot from Feast, which achieves this unification as a software-level abstraction. Still, it sounds cool if you’re starting from scratch.
DuckDB: Is Spark dead already??
Next-up on the line was DuckDB. I am always excited about DuckDB.
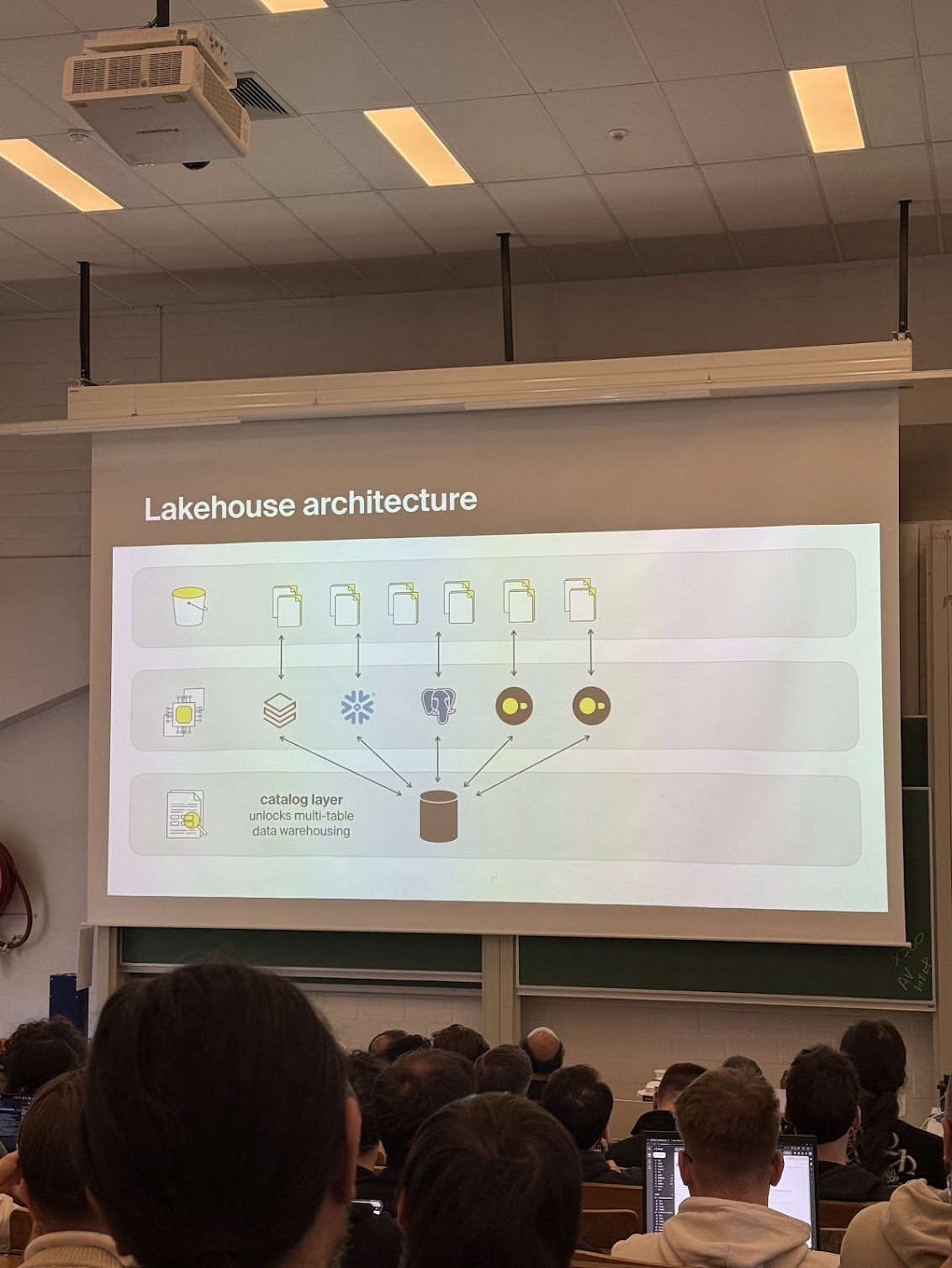
DuckDB has somewhat recently unveiled its Iceberg support. It’s realistically read-only, since they don’t support upserts (merge into), which is highly critical for idempotent writes. I gave it a shot once , and it seems it has limitations for some catalog types as well. Despite these drawbacks, the progress is clear, and I bet in a few years or so Iceberg ecosystem will reach similar maturity as Parquet, with different mature implementations in various languages. Just a few more years, and you can drop Spark - for medium data use-cases though.
Grafana Labs: SQL + Analytics for operational metrics

Lastly, I was surprised to learn that even Grafana Labs is spearheading a SQL + analytics stack like dbt as a valuable technology direction on top of operational use cases. That’s such an understatement, in my opinion — DWHs love appends, and operational metrics are all time-series appends; alerts and metrics are really just windows + group-bys on columns. Perfect efficiency! And when was the last time you actually enjoyed writing PromQL?
Lunch Break
Time for lunch. The typical FOSDEM menu is slightly overpriced, fuel-like food: burgers, fries, pizzas. But hey, can’t complain; the conference itself is free.

Containers, ML models as containers?
Having fueled myself—and knocked back an espresso shot — I rushed back, this time to the containers track room. I wanted to see something new, outside of databases and Python.

Basically, docker model run. Did Docker eventually manage to create a perfect ML model packaging format? The model, its dependencies, I/O schemas—able to run in any container-like environment? Only for LLMs, though…
In essence, you can package your favorite LLMs supported by frameworks like VLLM into an OCI-compatible artifact, storing it on GCP’s Artifact Registry or your own hosted registry (argument: you don’t want private stuff on HuggingFace). Neat—but I was really hoping they had solved this for any arbitrary model, like scikit-learn with custom preprocessing (and maybe even beat MLflow).
Apache Arrow: The Future of Data Exchange
Next on the line was the Apache Arrow talk:

I had been waiting for the Apache Arrow talk. Matt is an engaging presenter. Arrow remains a common in-memory format, allowing different systems to communicate without serializing or deserializing data.
An argument he focused on this year is that row-based communication, like JDBC, is wasteful. Since most sources have mostly converged to columnar memory layouts, transferring data in columnar Arrow format eliminates the need to transpose it. CPU is the bottleneck, not network speed anymore. Hence comes Columnar, building a faster JDBC with Arrow at its core.
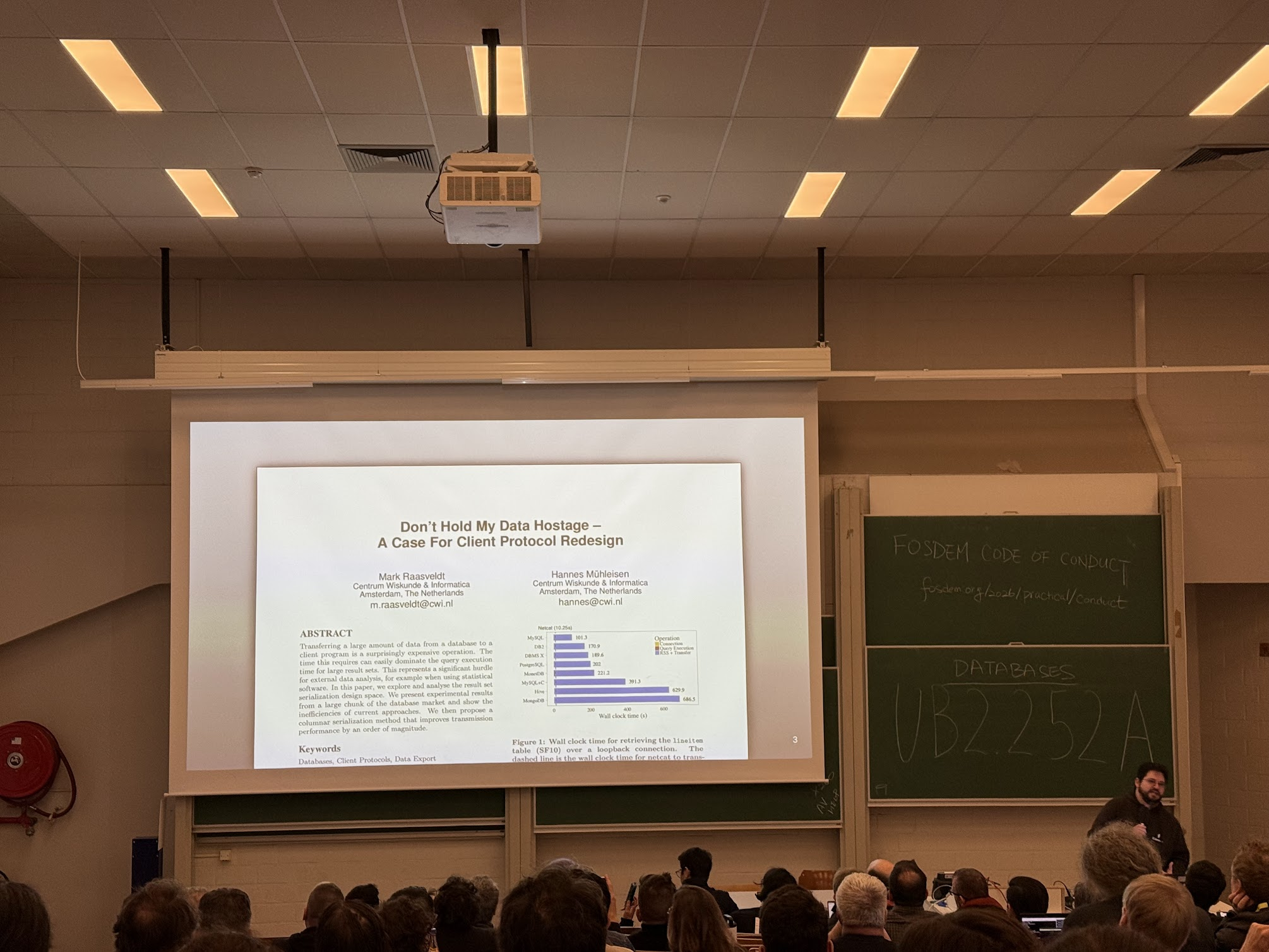
Read up on why exchanging data in columnar format is so beneficial in this rather historical paper (from 2017, haha) by one of the DuckDB co-authors.
Lakehouse Migration for Streaming: Lessons Learned
A cherry on top of the day was this talk on a lakehouse migration for a high-write streaming stack:

The talk served as an assurance for us, since we are exploring the lakehouse architecture at my current workplace.
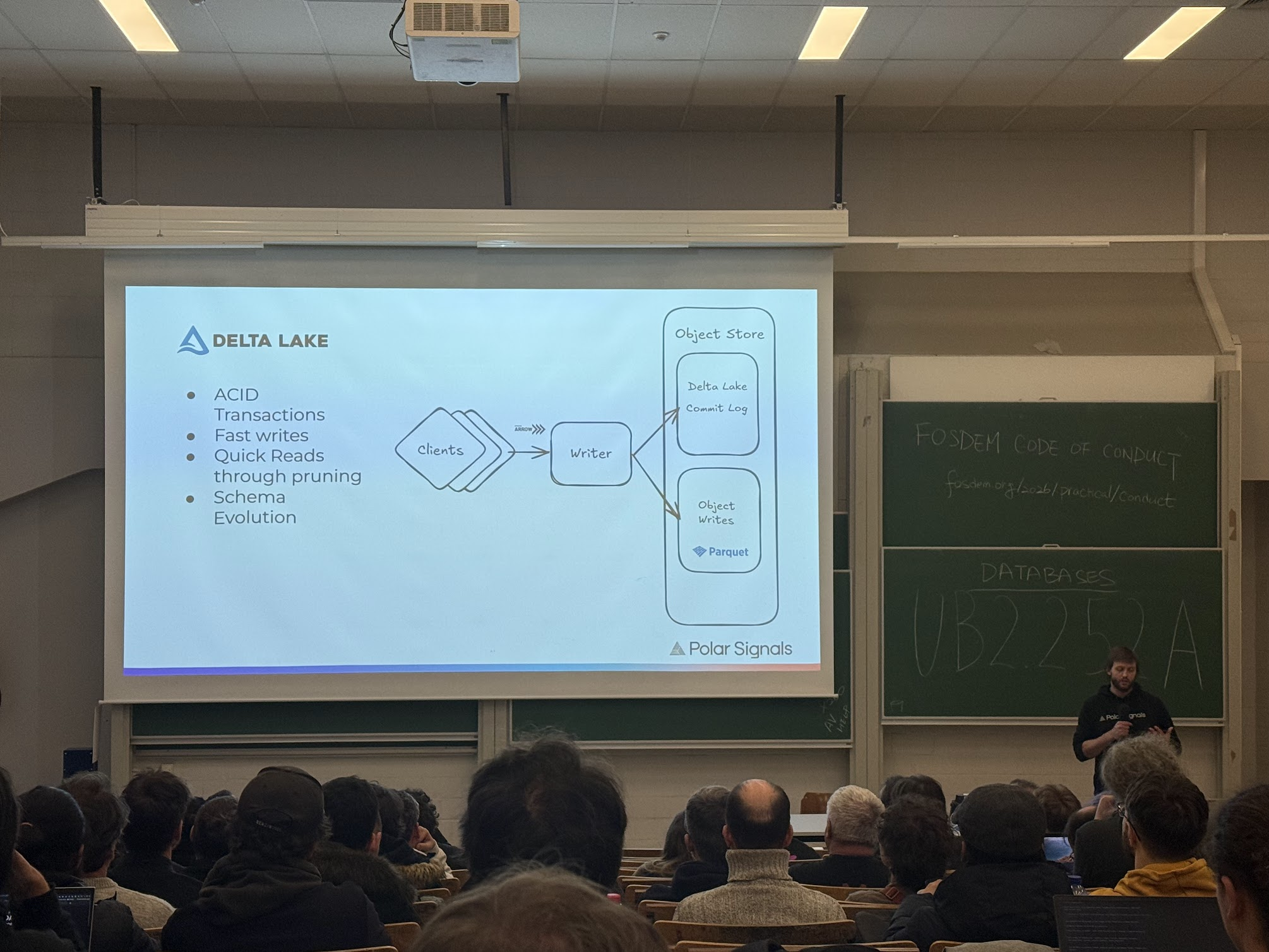
They moved from a classic shared-nothing DB to shared-everything on object storage. In shared nothing approach, each node holding the full state to avoid read/write bottlenecks. This causes storage to balloon (multiply with each replica), also crashed replicas can’t serve since they need to be catching-up from WAL. By switching to stateless nodes with the Rust-based DataFusion query engine, they cut costs by 50% (no replica storage duplication) and improved speed (thanks to DataFusion itself mostly). An architecture usually reserved for DWHs, I was genuinely surprised they pulled this off for streaming.

Eventually, unwinded after the day with some 9% Belgian beers.
Day 2: Rust and Python
The previous day, we had discussed with some colleagues that the next day looked rather empty. Overall, it did turn out to be less packed than the first one, but nonetheless — punchy.
I started the day meeting an old colleague. The first few talks were a miss, thanks to the classic mistake of focusing too much on the details.
We eventually sneaked into the Rust track, packed full, for the talk by ClickHouse’s CTO himself!
Clickhouse: C++ to Rust

Engaging delivery on ClickHouse’s journey from C++ to Rust. The CTO argued it only makes sense to swap C/C++ for Rust if:
- There’s a Rust extension with a significant community around it, whereas C++ doesn’t have one. A good example is
delta-rs, a Rust-based delta-log implementation ClickHouse adopted to support reading and writing from Delta Lakehouses. - Rust is cool. It serves as a marketing tool to attract maintainers.
On the other hand, a full rewrite is a bad idea because:
- Rust is too hyped—its underlying value might turned out to be often lower than it seems.
- Separate dependency management can be tricky. For example, ClickHouse had issues with both baked-in OpenSSL and the system’s dynamically linked OpenSSL, because the Rust dependency relied on a transitive version that differed from the C++ setup.

ty: The Fast Python Type Checker
Energized, we all jumped from Rust for databases into Rust for Python developer tooling. Meet Ty - the new fast Python type checker.
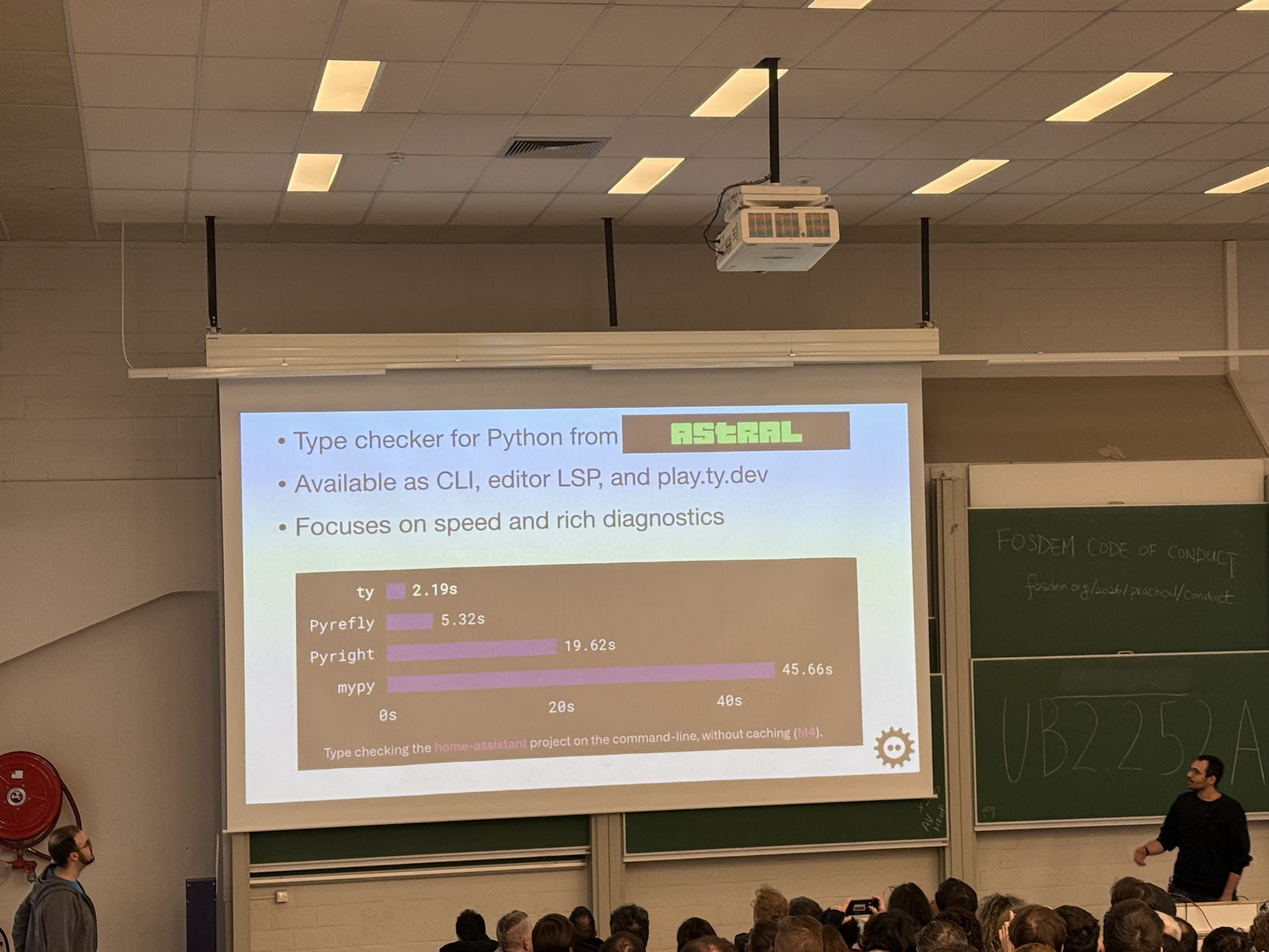
The main point — ty is fast not just because it’s written in Rust, but also because it leverages incremental computation. Whenever part of your source changes, it only recomputes the dependent parts for type checking. Ty’s been out of beta for a while—definitely give it a shot!
Wrap-up
We ended the day in one of the many FOSDEM indoor cafés, with some beers and fries. Met a few old colleagues, so we eventually skipped the rest of the presentations just to catch up…
Intense, knowledge-packed, social weekend. Hard to pin down a main theme — there was a bit of everything for everyone. That’s FOSDEM. See you in 2027!